How the X 'For You' Feed Works
Table of Contents▾
xAI pushed a new release of xai-org/x-algorithm — the source code that decides which posts you see in the "For You" tab on X. The repo is dense. The actual ideas inside it are not. This post is a guided walk through those ideas, building up from the problem the system is solving to the architecture that solves it.

Roughly one billion candidates at the top, fifty slots at the bottom — a 20-million-to-one funnel that has to run in a few hundred milliseconds.
Start with the problem, not the solution
Before reading a single line of architecture, it helps to feel the constraint the engineers are working against.
Every time you open X, the app has to answer one question:
Out of the roughly one billion posts written in the last few days, which fifty should I show this person right now, in the next few hundred milliseconds?
Pause on that for a second. A billion candidates. Fifty slots. Hundreds of milliseconds.
The ratio between input and output is something like twenty million to one, and the whole thing has to feel instant.
You cannot score a billion posts with a neural network in 300 ms. Even if each score took one microsecond, you'd need 17 minutes.
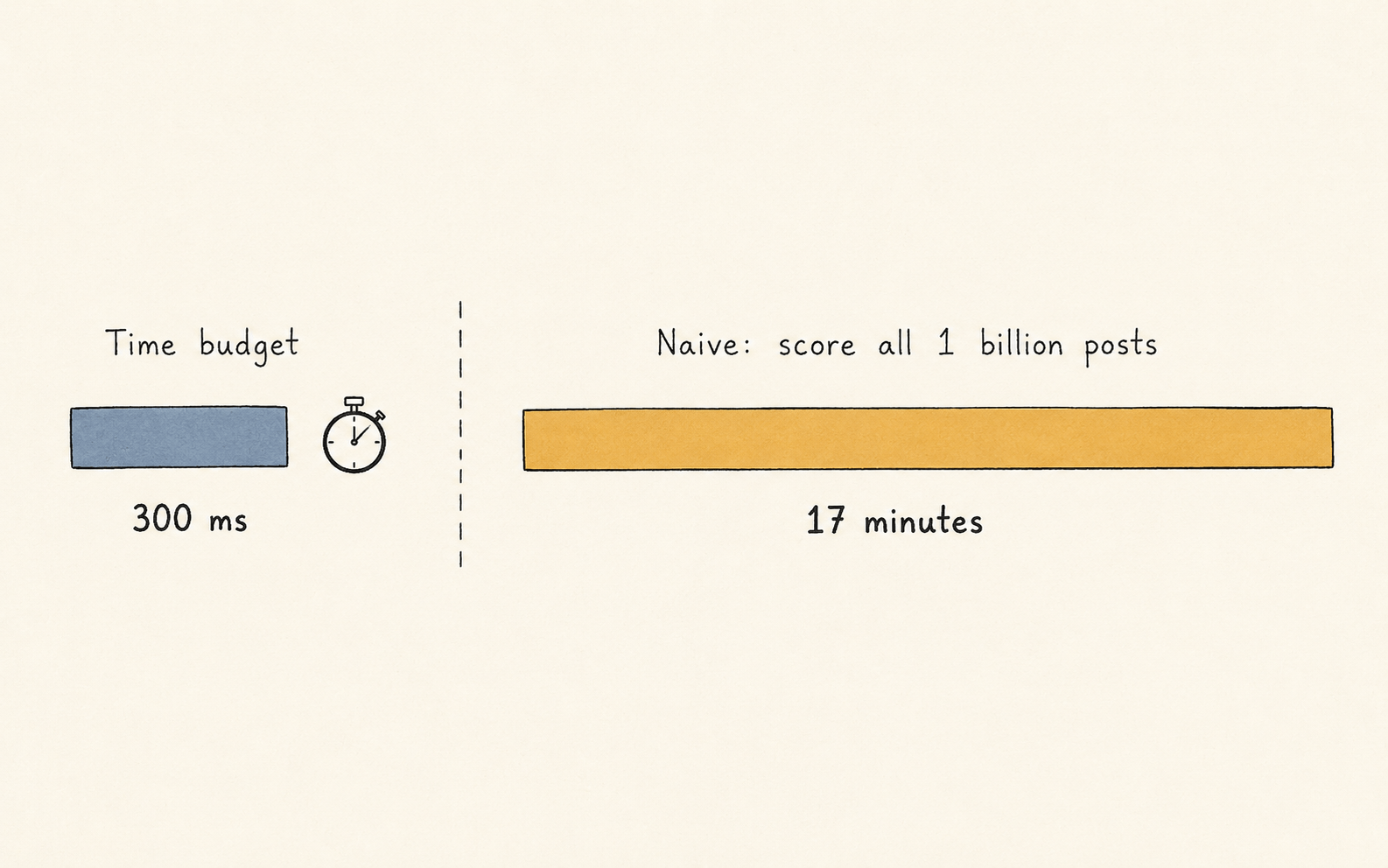
Scoring all candidates naively would take 17 minutes — about 3,400× the 300 ms time budget. That ratio is why the system has to be a funnel rather than one big model.
So the system can't be one big model — it has to be a funnel, where each stage is cheap enough to handle the volume flowing into it and expensive enough to actually be useful at narrowing it down.
That funnel shape is the single most important idea in the codebase. Everything else exists to fill in a stage of it.
The funnel, stage by stage
Here is the funnel, top to bottom. We'll then zoom into each stage.
- Candidate sourcing. Pull a few thousand "maybe relevant" posts from the billion. Cheap per post. This is done by two services: Thunder, an in-memory store that tracks recent posts from accounts you follow, and Phoenix, a learned model that retrieves posts from accounts you don't follow.
- Filtering. Throw out the obviously-bad ones — duplicates, things you've already seen, posts from accounts you've blocked. Still cheap.
- Scoring. Run a transformer to predict, for each remaining candidate, how likely you are to engage with it. Expensive per post, so this only happens after the count is down to thousands.
- Selection. Sort by score, take the top K, dedupe one more time, ship to your phone.
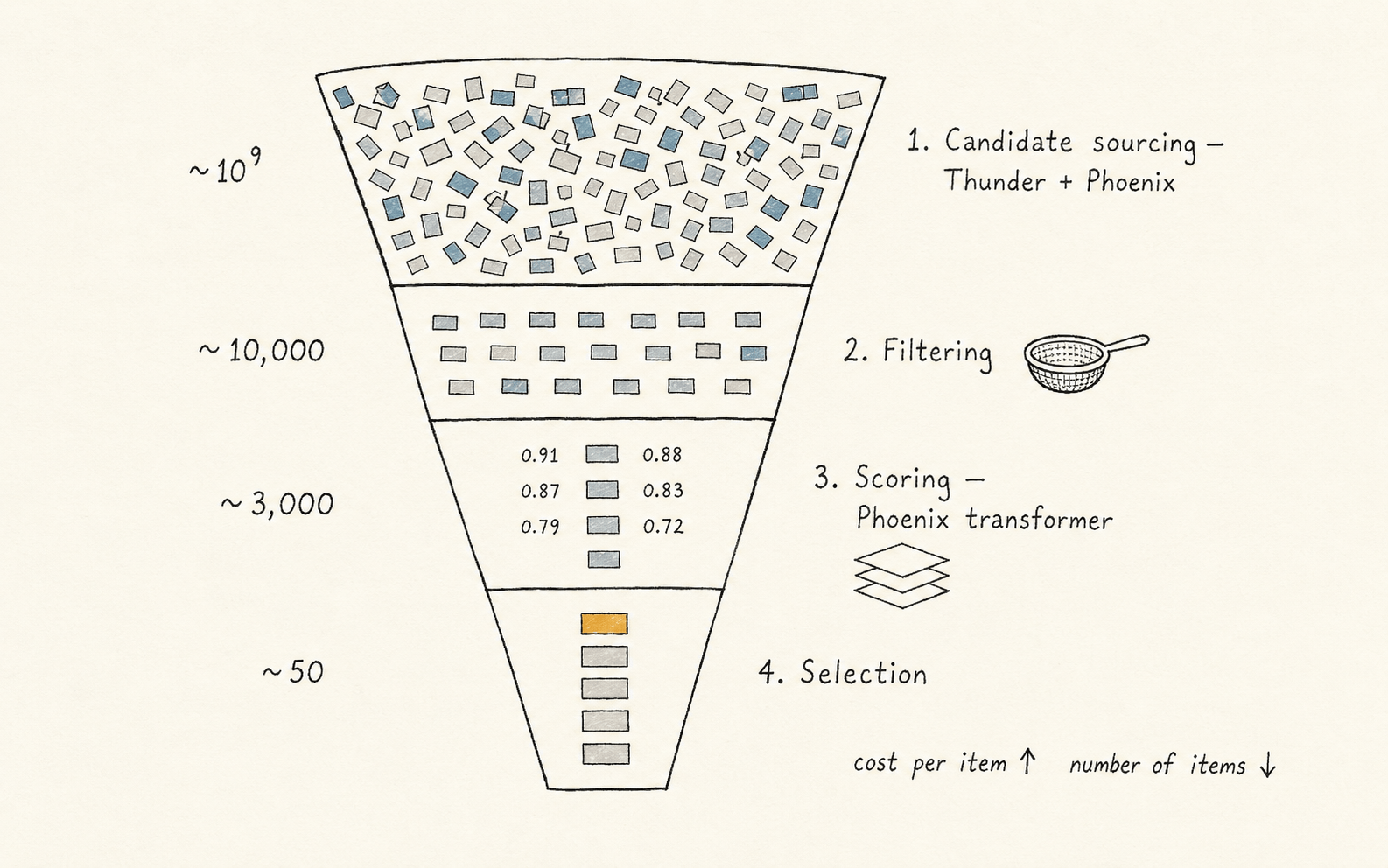
Notice the pattern: as you go down, the cost per item goes up and the number of items goes down.
That's how you stay inside the time budget.
Stage 1, part A: finding posts from people you follow
Let's zoom into the top of the funnel.
The easier half of candidate sourcing is in-network — posts from accounts you already follow. Conceptually this is just a database query: "give me recent posts from these 800 user IDs."
The hard part is doing it in single-digit milliseconds for hundreds of millions of users simultaneously.
The system's answer is a service called Thunder. The trick is: don't use a database at all.
Instead, Thunder is an in-memory store that subscribes to the Kafka topic of post create/delete events. As posts get written across the platform, Thunder updates its in-RAM data structures in real time, keeping per-user lists of:
- original posts
- replies and reposts
- video posts
…all trimmed to a retention window (recent posts only — anything older falls off).
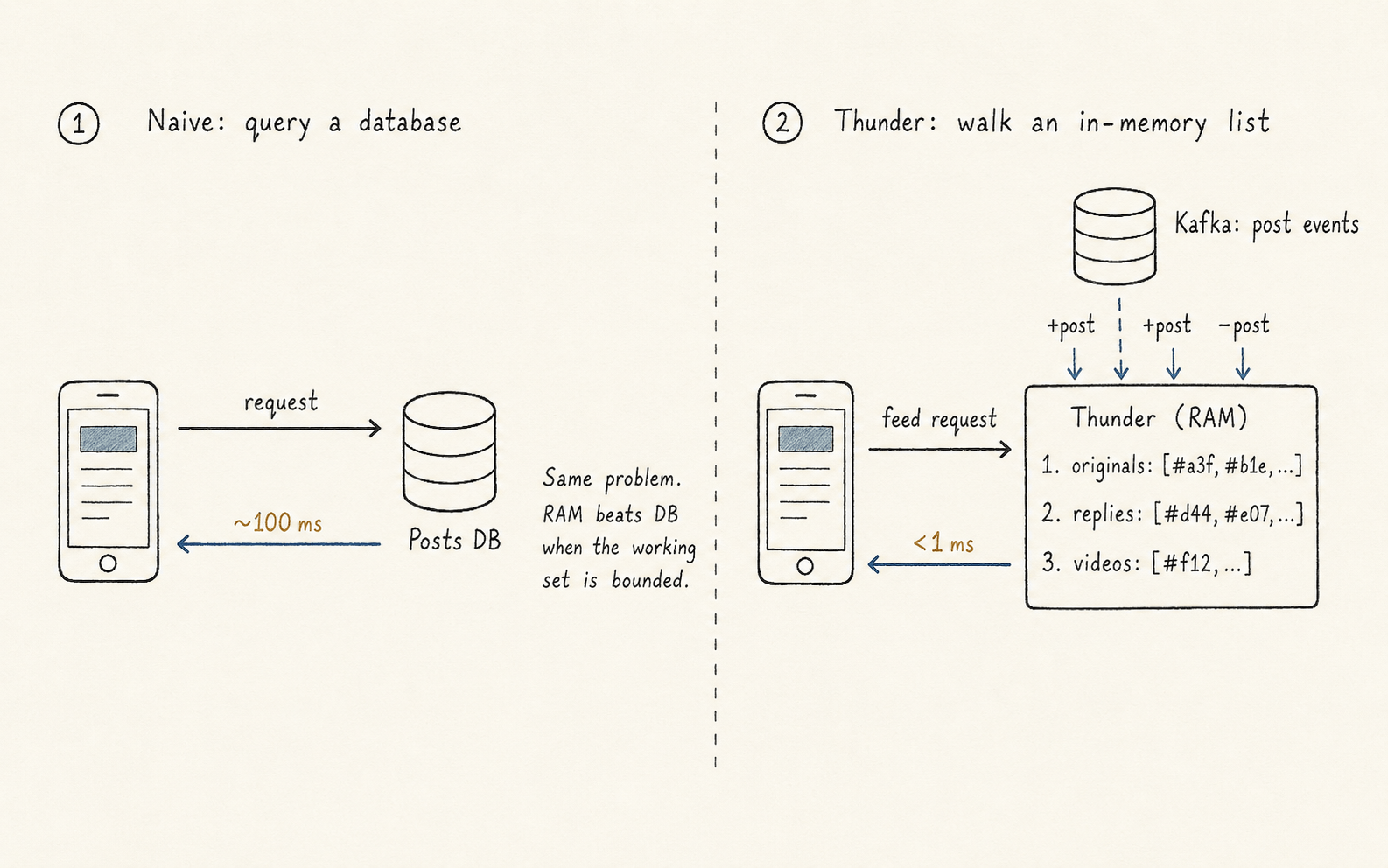
Same problem. RAM beats DB when the working set is bounded.
When a feed request comes in, Thunder doesn't query anything; it just walks the in-memory lists for the accounts you follow. That's how you get sub-millisecond lookups at this scale.
The cost is RAM and the engineering work of keeping that RAM consistent with reality — both of which X is willing to pay.
Lesson: when latency is the dominant constraint and the working set is bounded, "put it all in memory and update incrementally" often beats "query a database faster."
Stage 1, part B: finding posts from people you don't follow
In-network is easy because the candidate set is small and explicit. Out-of-network is the interesting problem: out of everyone on X, which posts that you've never seen, from accounts you've never followed, should you see?
You can't enumerate them. You need a way to search the global post corpus for things "like" what you've engaged with before.
The solution is a model called Phoenix, and the architecture is worth understanding because it shows up everywhere in modern recommender systems — Google's YouTube two-tower paper and Pinterest's PinSAGE use the same shape.
Building up to two-tower retrieval
Here's the move.
Imagine you could represent every user as a point in some high-dimensional space, and every post as a point in the same space, such that the geometric closeness of a user-point and a post-point corresponds to how much that user would like that post.
If you could do that, recommendation would reduce to: "find the post-points closest to this user-point." That's a problem computer science has been solving for decades — it's nearest-neighbor search, and there are libraries (FAISS, ScaNN, Annoy) that do it in milliseconds even for billions of points.
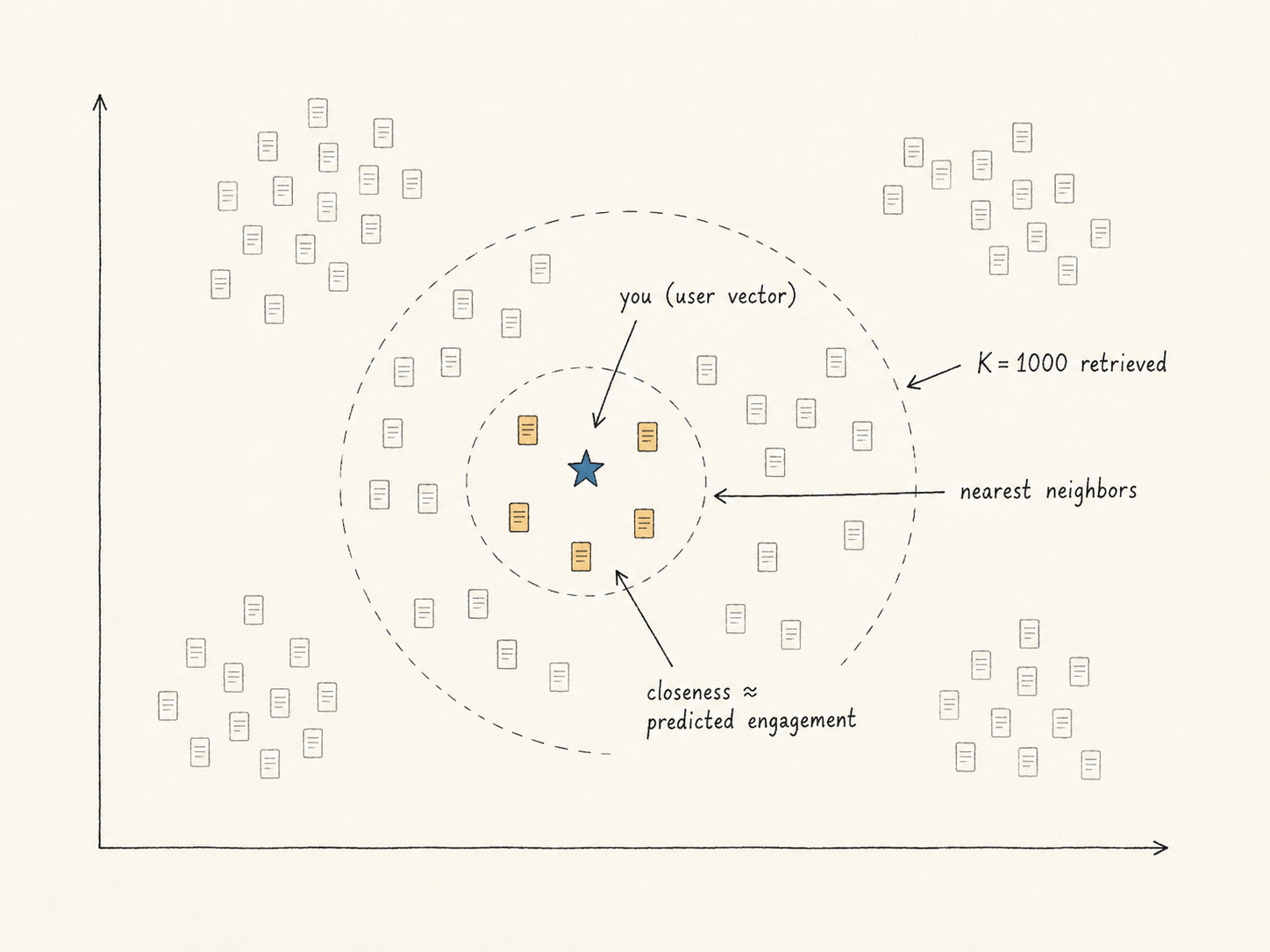
Every user and every post becomes a point in the same 256-dimensional space. The user vector stays slate-blue across the rest of this post — track it.
So the question becomes: how do you learn that shared space?
The answer is the two-tower architecture:
- A User Tower is a neural network that takes your features — recent likes, replies, follows, language, the times you opened the app — and outputs a 256-dimensional vector. That vector is your point in the space.
- A Candidate Tower is a separate neural network that takes a post's features and outputs a 256-dimensional vector in the same space. That vector is the post's point.
- During training, both towers are optimized jointly so that for every (user, post-they-engaged-with) pair, the dot product of the two vectors is high, and for (user, random-other-post) pairs the dot product is low.
After training, you precompute every post's vector once and dump them into a vector index. At serving time, you compute your vector on the fly and ask the index for the K closest post-vectors. Done.
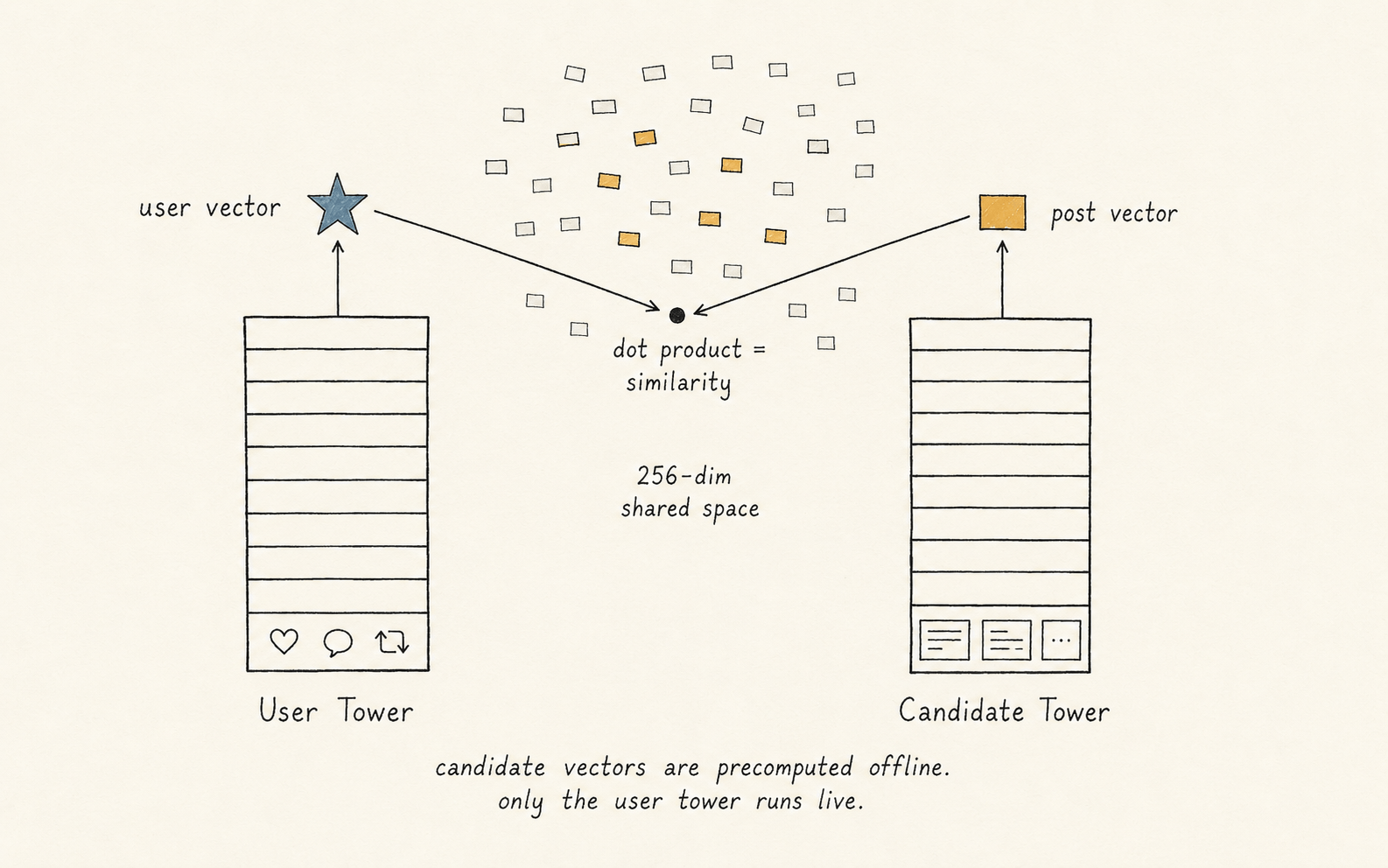
This is why it scales: the expensive part (running the Candidate Tower over a billion posts) happens offline, in batch.
The hot path only runs the cheaper User Tower and does a nearest-neighbor lookup.
That's stage 1, part B: a billion posts became a few thousand.
One detail: hash-based embeddings
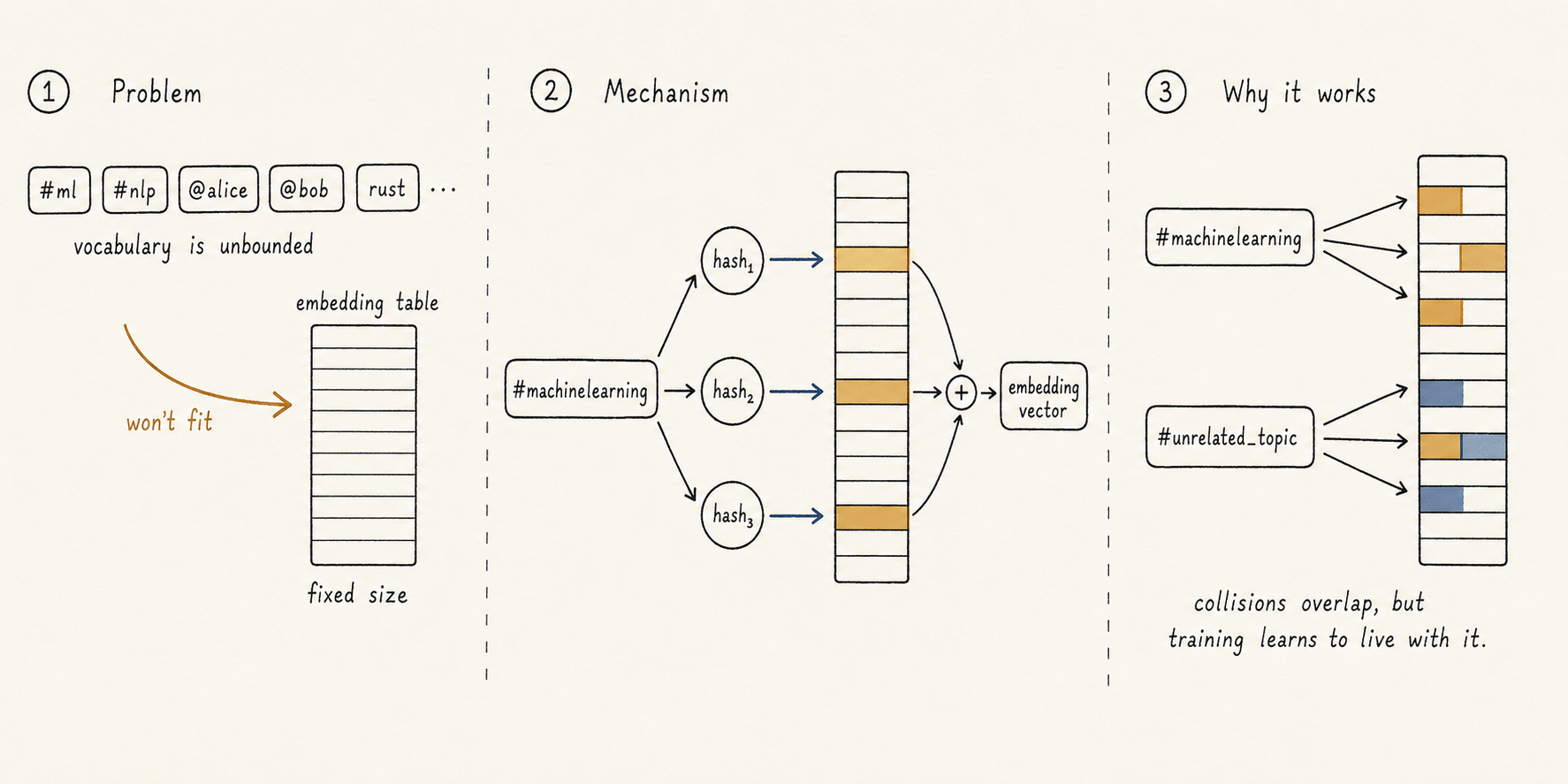
The towers can't have a learned vector for every possible username, hashtag, or word — the vocabulary is unbounded and growing every second.
Phoenix sidesteps this with hash-based embeddings: every feature ID is passed through multiple hash functions, each hash points to a row in a fixed-size embedding table, and the rows are summed. Collisions happen, but training learns to make them tolerable.
The result: an unbounded feature space mapped into a bounded parameter budget.
Stage 3: scoring, and why "one number" isn't enough
After stages 1 and 2 you're left with maybe a few thousand candidates. Now you have to put them in order.
This is where the heavy ML happens.
Phoenix has a second component, a transformer-based ranker built on the same architecture as Grok-1, adapted for recommendation. (If you want a primer on transformers themselves, Jay Alammar's The Illustrated Transformer is the classic.)
For each candidate post, it predicts not "is this relevant" but a vector of probabilities — one per type of engagement you might have.
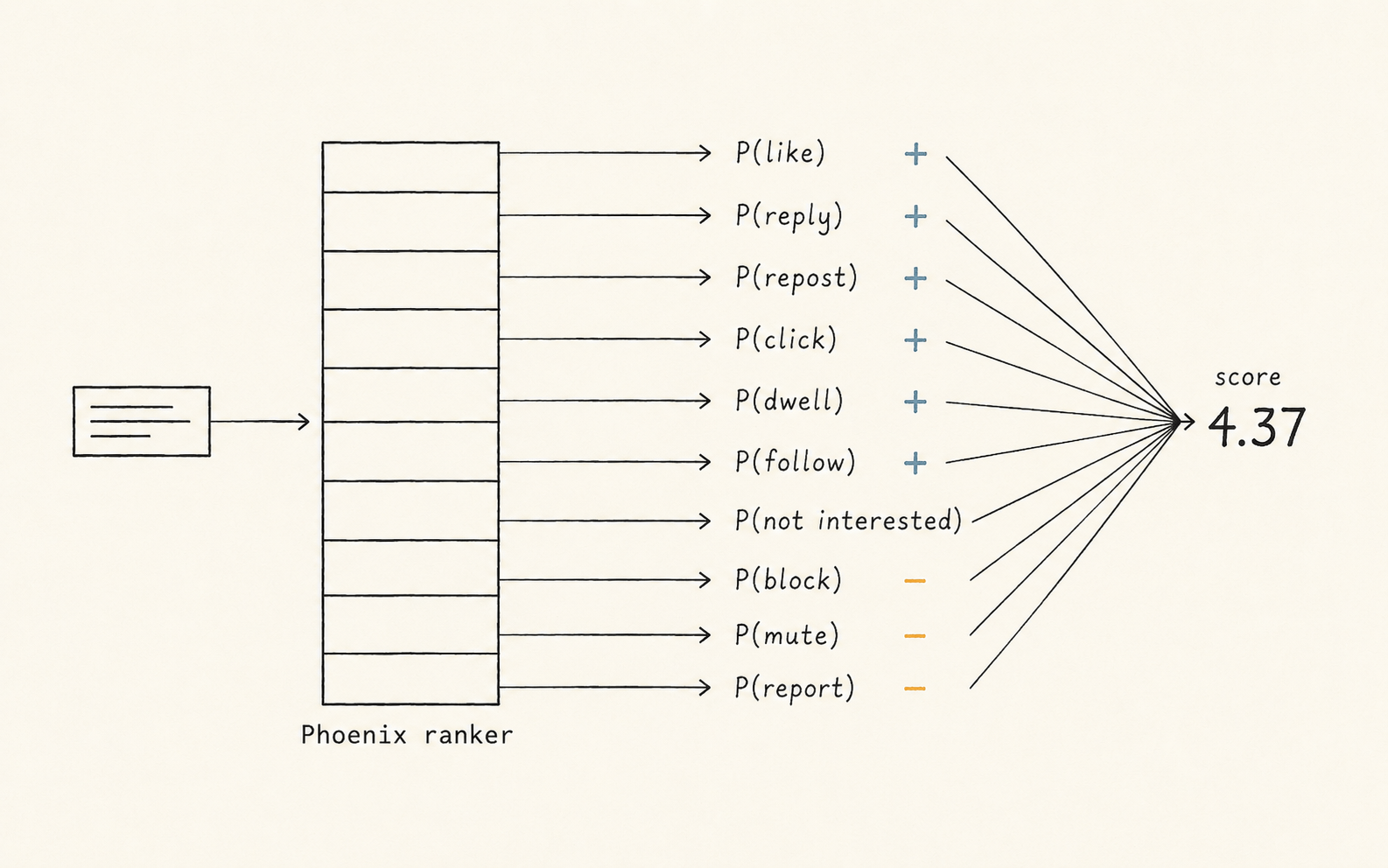
The positive ones:
- P(like)
- P(reply)
- P(repost)
- P(quote)
- P(click)
- P(profile click)
- P(video view)
- P(photo expand)
- P(share)
- P(dwell)
- P(follow author)
…and the negative ones, which matter just as much:
- P(not interested)
- P(block author)
- P(mute author)
- P(report)
Why predict fifteen probabilities instead of one?
Because "engagement" isn't one thing. A post that you'd click on but never reply to is different from one you'd reply to but never share, and the platform's goals (long-term retention, content quality, ad relevance) trade off across those actions differently.
The final score is a weighted sum:
score = Σ wᵢ · P(actionᵢ)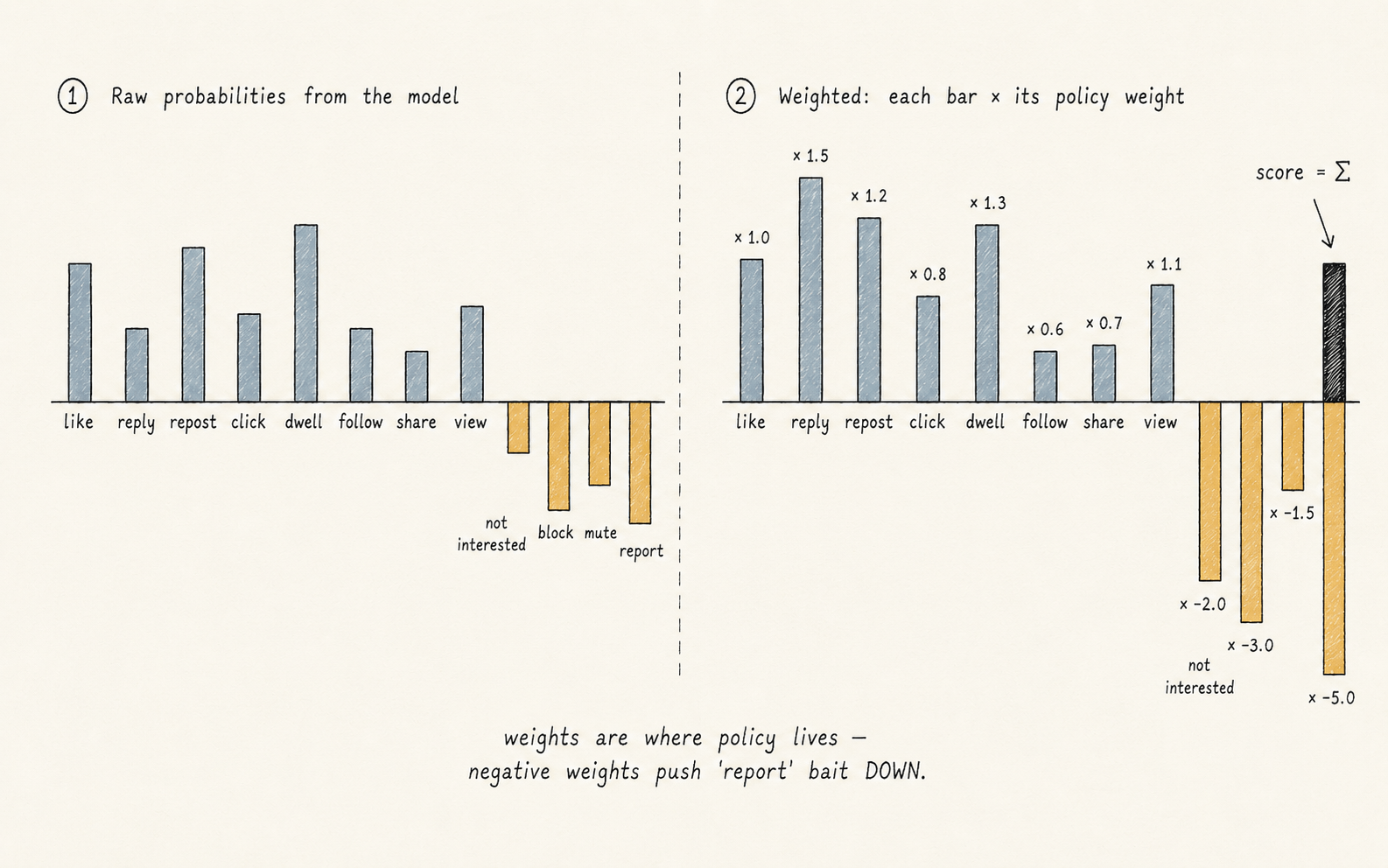
Weights are where policy lives. A negative weight on P(report) lets the model push a post down even if you might also click on it.
Positive actions get positive weights. Negative actions get negative weights, which means the model can push down a post it predicts you would report or block — even if you might also click on it.
That single line of arithmetic is where the platform's content policy gets expressed numerically.
Why candidates can't see each other
There's a subtle architectural decision here that's worth lingering on.
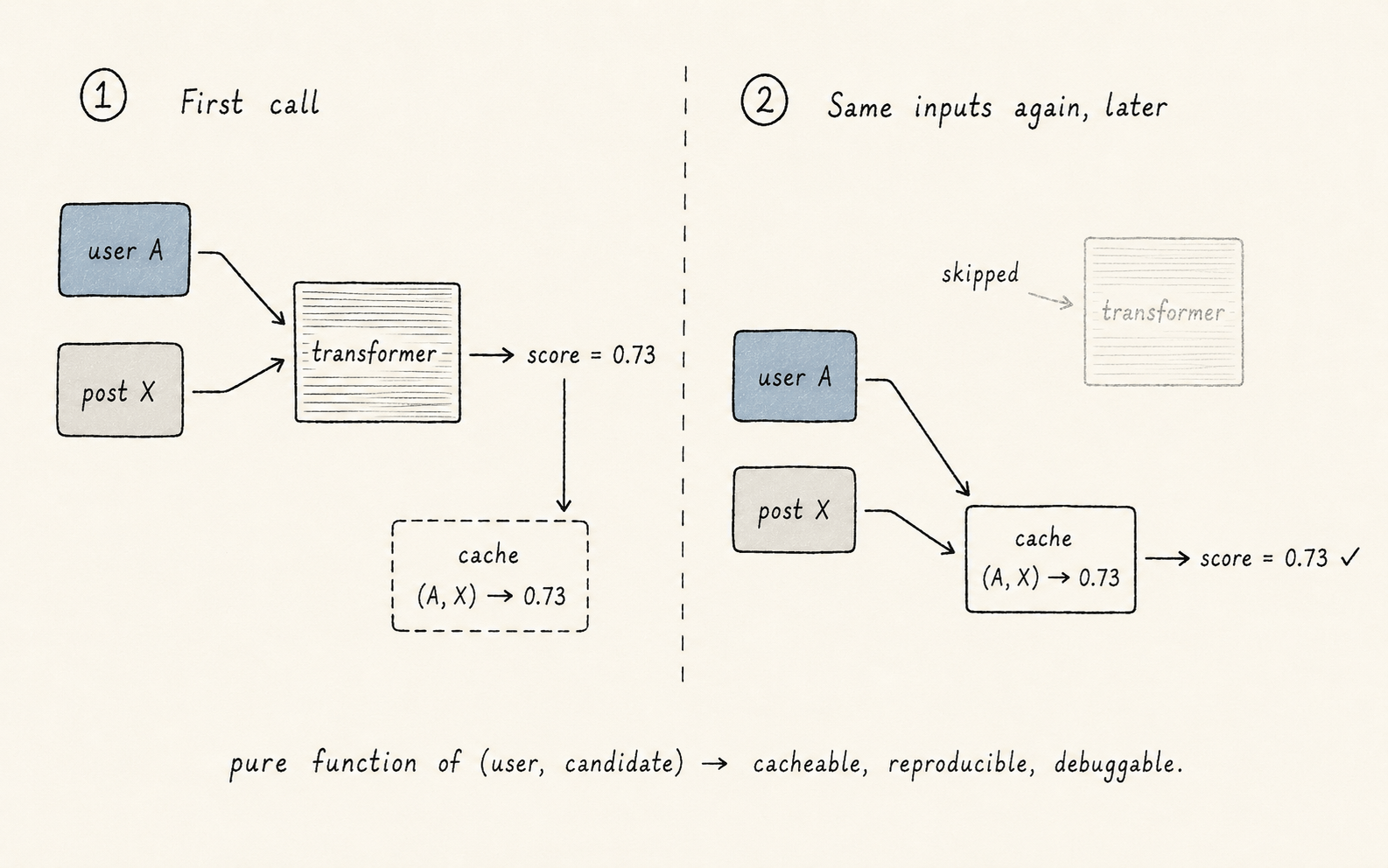
When the transformer scores a batch of candidates, the attention mask is block-diagonal: your user context attends to itself freely, and each candidate attends to the user context plus only its own tokens. No candidate-to-candidate attention.
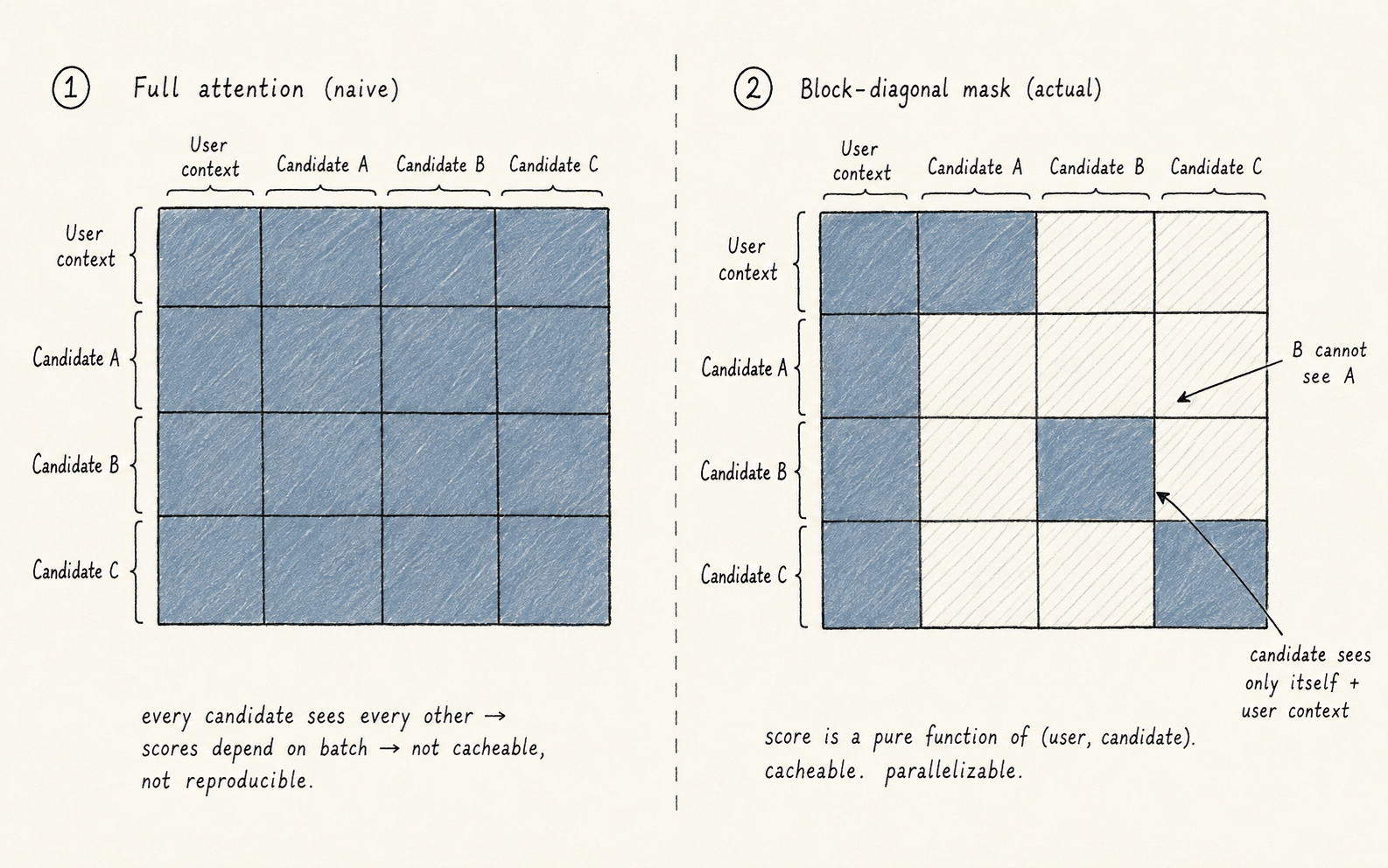
This sounds like a limitation, and in one sense it is — the model can't say "the batch already has three sports posts, downrank this fourth one."
But the upside is enormous: a post's score is now a function of only the post and the user. The same post scored against the same user always returns the same score, regardless of what else is in the batch.
That means:
- Scores are cacheable.
- Scores are reproducible.
- Scoring can be parallelized trivially — every candidate is independent.
Batch-level reasoning (diversity, dedup, freshness) is handled by downstream scorers running after the transformer: an Author Diversity Scorer attenuates repeated authors, an OON Scorer adjusts out-of-network content, and a conversation-thread filter dedupes branches of the same argument.
Cleanly separated concerns.
Stage 2 (revisited): the filters in the middle
We skipped past filtering, but it's where most of the candidate count actually disappears. There are two filter passes.
Pre-scoring filters, which trim the candidate set before the expensive transformer runs:
| Filter | What it removes |
|---|---|
DropDuplicatesFilter | Duplicate post IDs |
AgeFilter | Posts older than the cutoff |
SelfpostFilter | Your own posts |
RepostDeduplicationFilter | Reposts of content you'd already see |
IneligibleSubscriptionFilter | Paywalled content you can't access |
PreviouslySeenPostsFilter | Posts you've already viewed |
PreviouslyServedPostsFilter | Posts already served this session |
MutedKeywordFilter | Posts containing words you've muted |
AuthorSocialgraphFilter | Posts from blocked or muted accounts |
Post-selection filters, which run after scoring and selection, on the small final set:
| Filter | What it removes |
|---|---|
VFFilter | Deleted/spam/violence/gore |
DedupConversationFilter | Multiple branches of the same conversation |
Pre-scoring filters protect the budget of the transformer (don't waste an inference on a post the user can't see anyway). Post-selection filters protect the user from policy violations that slip through.
The split is intentional.
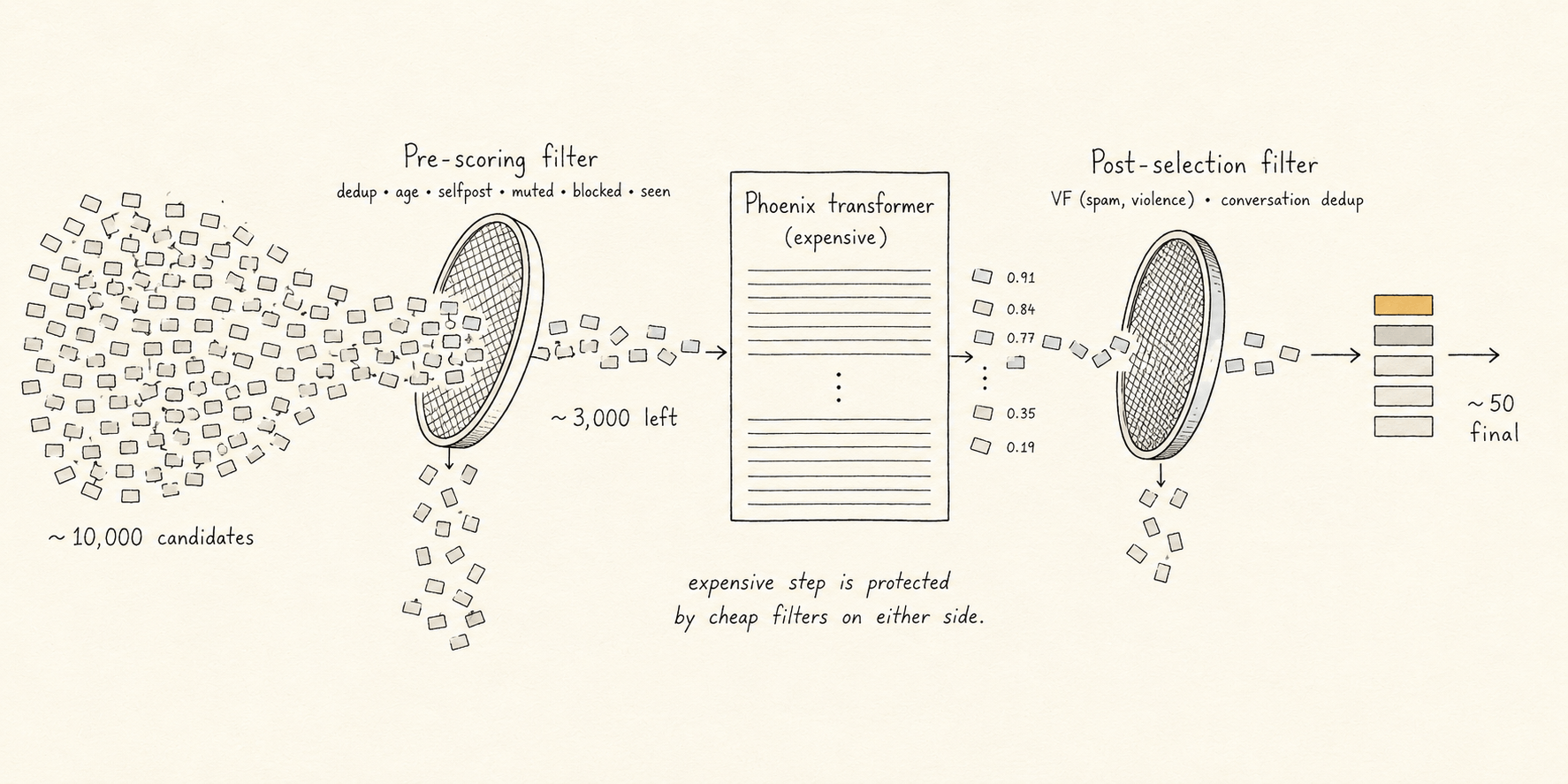
The expensive step is sandwiched between two cheap filters — each one protecting the budget of the next.
The plumbing that holds it together: Home Mixer
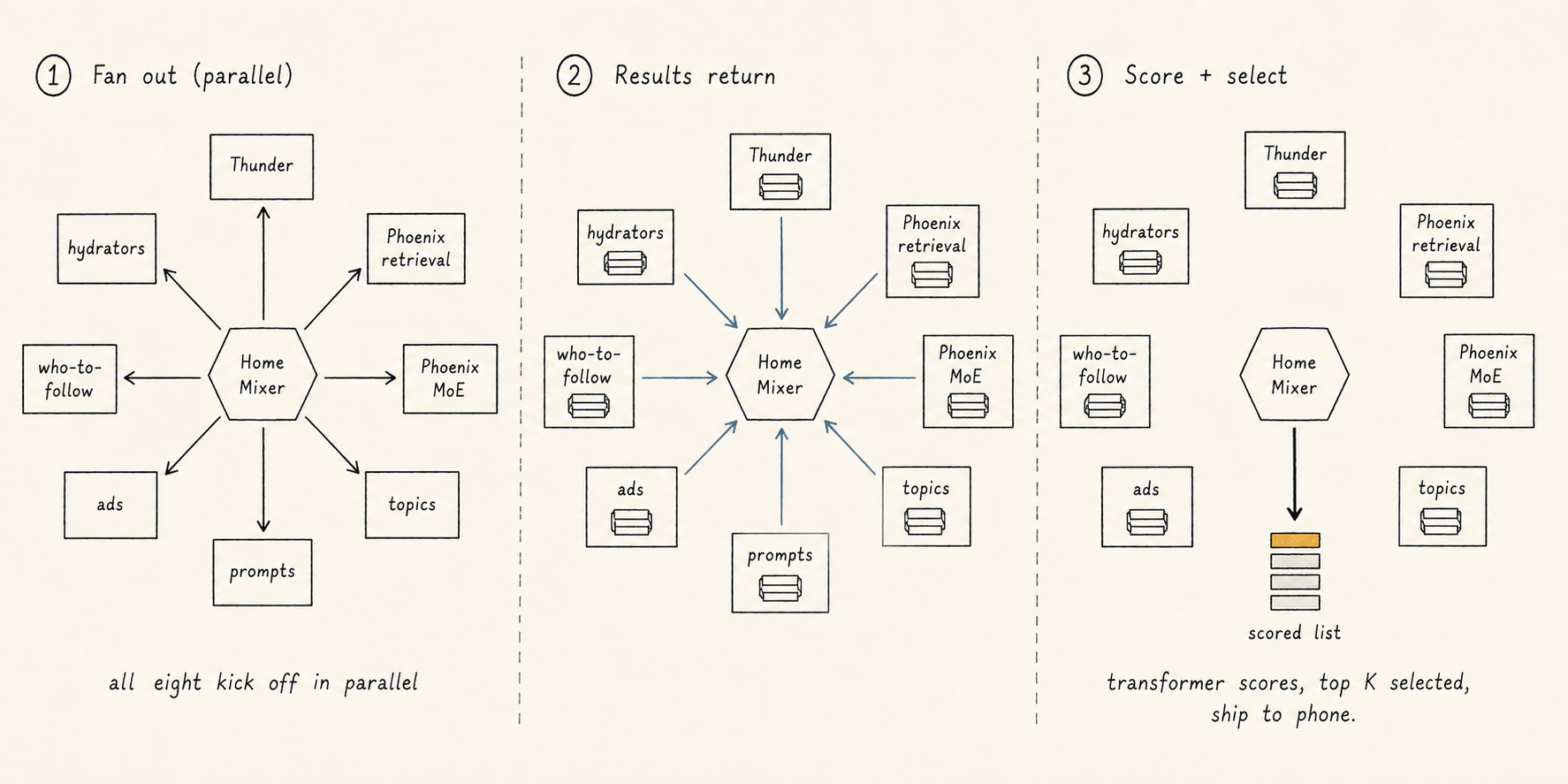
All of these stages — sourcing, hydration, filtering, scoring, selecting — are orchestrated by a service called Home Mixer, exposed over gRPC as ScoredPostsService.
When your phone asks for a feed, here's what Home Mixer does, in order:
- Query hydration. Fetch your user-level context: followed topics, starter packs, impression bloom filters (to avoid re-showing you posts), your IP, mutual-follow graphs, your recently-served history.
- Candidate sourcing. Run Thunder, Phoenix retrieval, Phoenix MoE, topics, prompts, ads, who-to-follow — all in parallel.
- Candidate hydration. For each candidate, fetch the post text, author info, engagement counts, brand-safety signals, language code, media metadata, quote-post expansions, mutual-follow scores.
- Pre-scoring filters. Apply the table above.
- Scoring. Phoenix ranker → weighted combiner → diversity scorer → OON adjuster.
- Selection. Sort by score, take the top K.
- Post-selection filters. VF, conversation dedup.
- Side effects. Cache the request, log impressions for the bloom filter and served-history.
The framework underneath this is the candidate-pipeline Rust crate, which defines a small set of traits — Source, Hydrator, Filter, Scorer, Selector, SideEffect — that each stage implements.
Independent stages run in parallel automatically. Adding a new candidate source means writing one struct that implements Source and registering it.
The pipeline doesn't need to be rewritten when the ML team ships a new model.
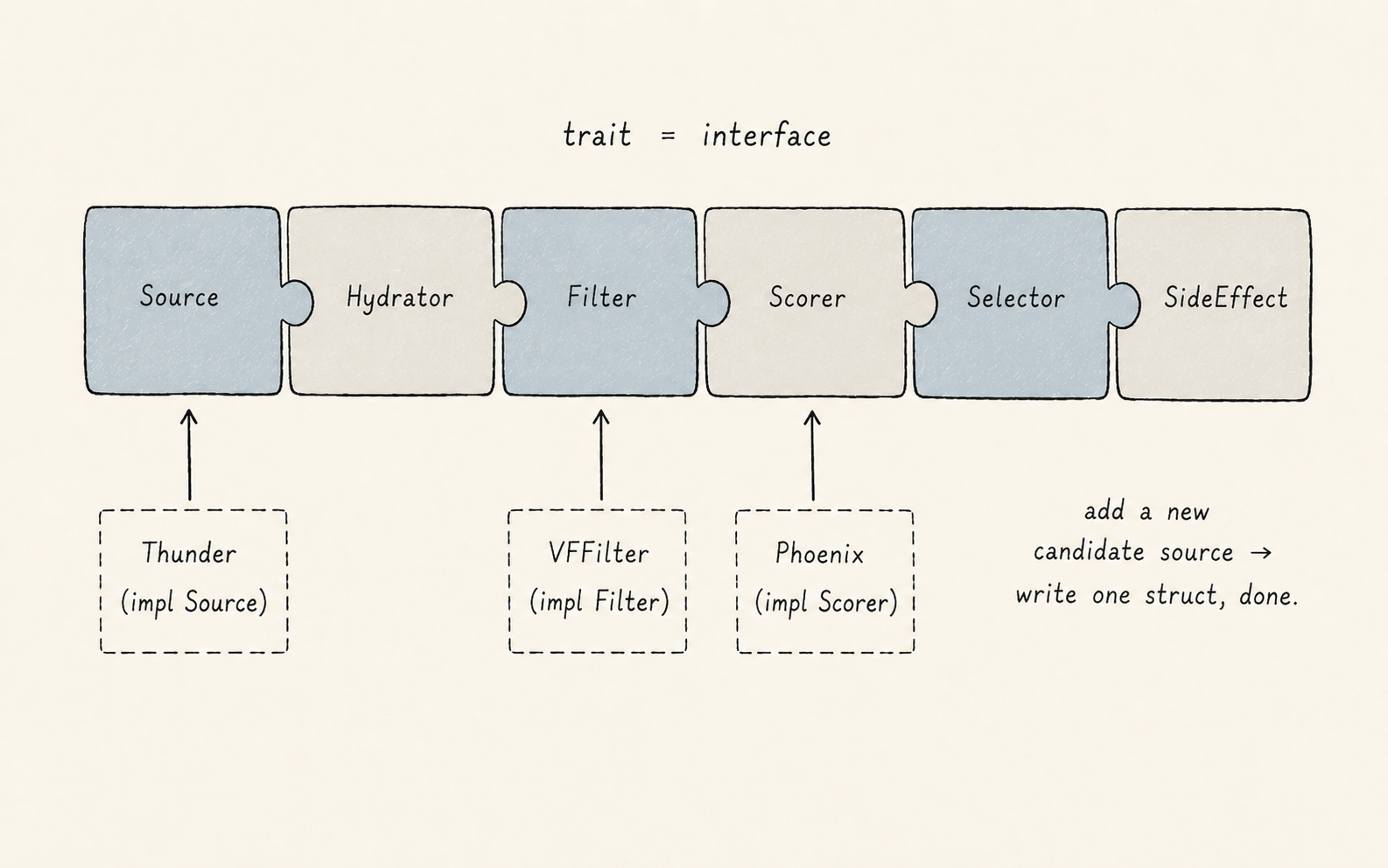
That's the architectural payoff of separating what a stage does from how the pipeline runs it.
Two design choices worth taking home
Step back from the code and look at the system. Two decisions stand out, and both are decisions you could apply outside of recommendation systems.
1. Let the model learn the features. Older recommender systems had engineers writing rules like "boost posts with images by 1.2x" or "downrank short replies." This one does not. The Phoenix transformer learns everything from your engagement sequence — text, media, timing, social graph — without anyone telling it what matters.
Fewer hand-tuned knobs means less code, less drift, and the model improves automatically as it sees more data. The trade-off is that you lose direct control: you can't easily say "show me more long-form posts today" with a config flag.
2. Make scores depend only on the input. The candidate-isolation trick — where each candidate's score is a pure function of (user, candidate) — makes everything downstream simpler.
Caching works. A/B testing works. Debugging works (the same post should get the same score; if it doesn't, you have a bug). Whenever you can design a system so that its outputs are pure functions of its inputs, do it.
The whole pipeline in one breath
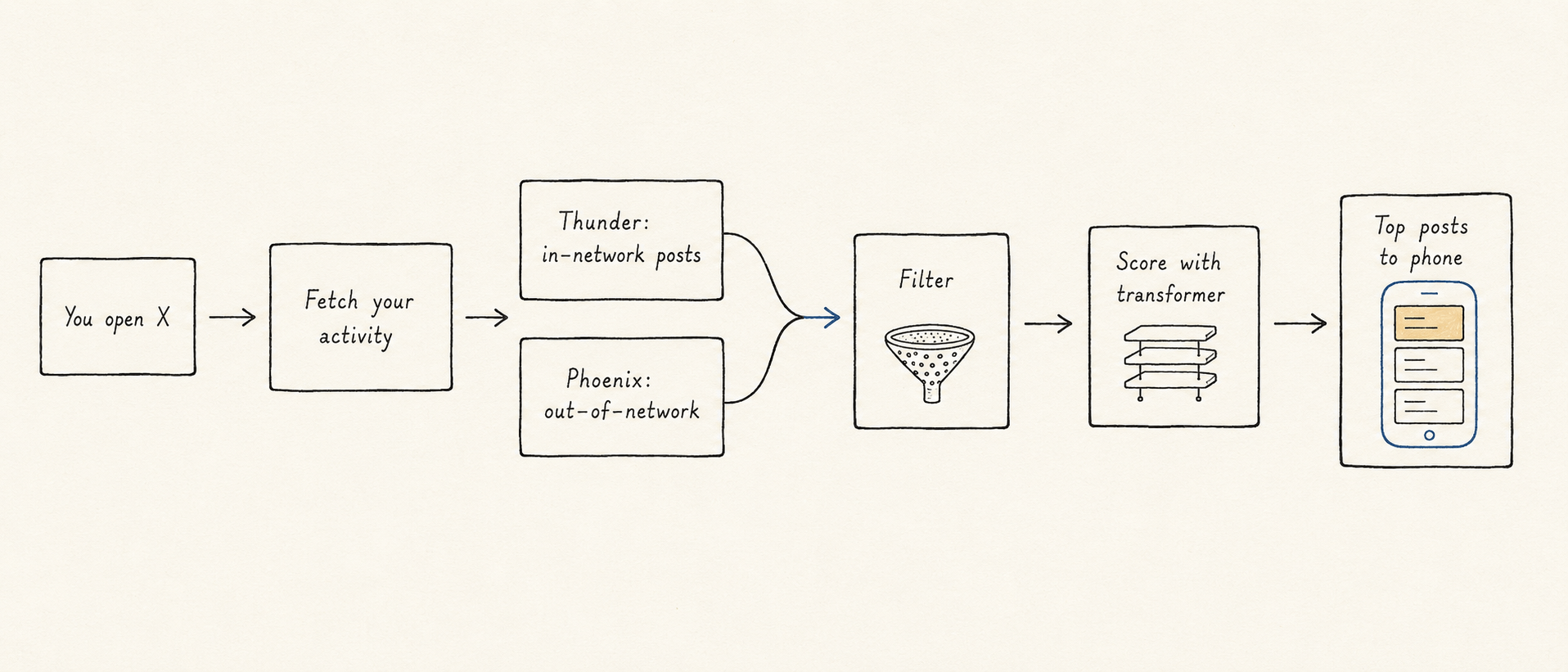
You open X. Home Mixer fetches your recent activity and context.
Thunder hands over fresh posts from people you follow; Phoenix retrieves a few thousand posts from across the platform whose vectors point in the same direction as yours.
Hydrators decorate every candidate with the metadata the filters and scorer need. Pre-scoring filters throw out anything you've blocked, muted, seen, or shouldn't see.
The Phoenix transformer scores what's left by predicting how you'll react along fifteen dimensions of engagement. A weighted sum collapses those predictions into a single score. Diversity, out-of-network, and ranking adjusters tilt the scores.
The top K are selected, deduped one last time, and shipped to your phone.
That's the For You feed. The codebase is just a careful, parallelized, cacheable version of this loop, broken into stages cheap enough to run on a billion-post corpus inside a few hundred milliseconds.
Once you see the funnel, the rest of the repo reads itself.